I'm looking for a measure (one single number) that represents how "concentrated" or "scattered" values are on a timeline.
See below example, where X might be years for example, and Y a quantity.
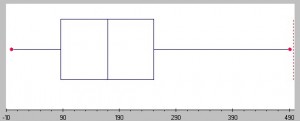
In Y1 and Y2 the higher values are lumped together ("concentrated"), whereas in Y2 and Y4 they are "scattered". Intuitively I'd score Y1 and Y2 high (and equally high since their "concentratedness" is the same, although offset in time), and Y2 and Y4 low. How do I calculate such a measure, and does it even exist?
Any help would be greatly appreciated!
(I'd like to get this done in Excel so if you know of an Excel/M/Dax formula, please let me know).

See below example, where X might be years for example, and Y a quantity.
In Y1 and Y2 the higher values are lumped together ("concentrated"), whereas in Y2 and Y4 they are "scattered". Intuitively I'd score Y1 and Y2 high (and equally high since their "concentratedness" is the same, although offset in time), and Y2 and Y4 low. How do I calculate such a measure, and does it even exist?
Any help would be greatly appreciated!
(I'd like to get this done in Excel so if you know of an Excel/M/Dax formula, please let me know).




") .
.